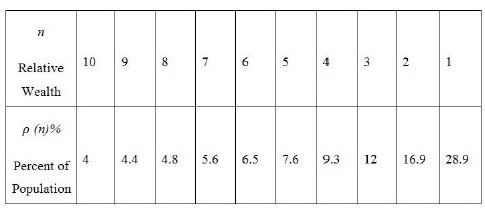
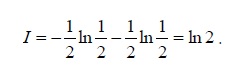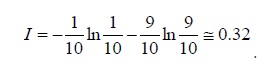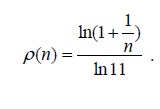Chapter 4
The Entropy of Information
The Distribution of Digits – Benford’s Law
Page 141 from the book
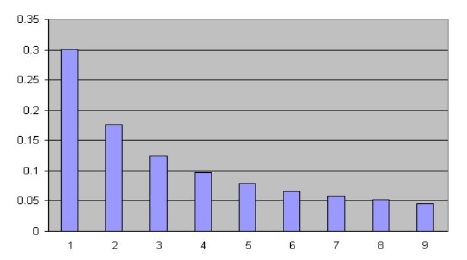
Figure 6: Benford’s law – the relative frequency of a digit in a file of random numbers in not uniform. The frequency of the digit “1” is 6.5 times greater than that of the digit “9”.
These results are counterintuitive, since we naturally expect a uniform distribution of digits. Yet the “1” digit appears 6.5 times more frequently than the “9” digit! The reason is that in equilibrium, each microstate has an equal probability, and thus every ball will have an equal probability of “drawing” any box. That is, in order to divide fairly P balls into N boxes, P drawings for N boxes must be performed. At each drawing, one box will “win” one ball. Obviously, the probability that in the end of our game one particular box will have won many balls is lower than the probability that it will have won only a few balls. Put simply, it is easier to win one ball than to win nine balls. Life is tough!
Does this imply that the second law of thermodynamics is also applicable to mathematics? Surprisingly, this very distribution –with the very same mathematical expression – was discovered empirically in 1881 by Canadian-American astronomer Simon Newcomb while he was looking at a booklet of logarithmic tables. (Before the era of the calculator, these tables were used for multiplication, division, finding the exponents of numbers, etc.) Newcomb noticed that the pages beginning with the digit “1” were much more tattered than the others. He concluded that if one randomly chose a digit from any string of numbers, the chance of finding the “1” digit is greater than finding any other digit. He examined the charts beginning with the digit “2” and so on, and came up with – as a conjecture – the very same formula that is derived in Appendix B-2.
In 1931, an employee of the General Electric Company, physicist and electrical engineer Frank Benford, demonstrated that Newcomb’s Law applied not only to logarithmic tables, but also to the atomic weights of thousands of chemical compounds, as well as to house numbers, lengths of rivers, and even the heat capacity of materials. Because Benford showed that this distribution is of a general nature, it is called “Benford's Law.” Since then, researchers have shown that this law also applies to prime numbers, company balance books, stock indices, and numerous other instances.
It should be noted, however, that if we were to allocate P balls among N boxes not by “drawing the lucky box” one ball at a time, but rather by using, for example, a top with ten faces bearing the digits “0” to “9”, and allowing each spin of the top to determine one digit in a non-biased way, the distribution of the digits among the boxes will be uniform. Why? It is clear that the digit symbol marked on any face of the top does not affect the probability of it falling on that particular side. This is why the various lottery games use such techniques for drawing numbers as give a uniform distribution, so that gamblers familiar with Benford's law will not have an advantage.
At first glance, Benford’s distribution seems counterintuitive, because we tend to regard digits as symbols rather than physical entities. The fact that most people are not aware of Benford's distribution is used by tax authorities in some countries to detect tax fraud by companies or individuals. If the distribution of digits in a balance sheet does not match Benford's law, the tax authorities suspect that the numbers have been fixed, and may launch a more thorough inspection.
To illustrate briefly the ideas presented more fully in Appendix B-2, let us examine a model of three balls and three boxes. The number of possible microstates (or configurations), according to Planck, is ten, as follows:
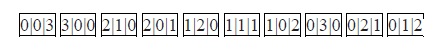
In equilibrium, each configuration has an equal probability. Thus we count the number of occurrences for each digit in all configurations. “1” occurs nine times, “2” occurs six times, and “3” only three. This is the distribution expected from the calculations in Appendix B-3 for the more general case (Planck-Benford), as applied to our case.
We therefore conclude that:
The distribution of digits in a decimal file that is compressed to Shannon’s limit obeys Benford's law;
Benford's law is the result of the second law of thermodynamics.
Mathematical operations have a physical significance.
In the next chapter we shall see that this distribution, when expanded from decimal coding to any other numerical coding (as we have just seen in the case of three balls and three boxes), can explain many phenomena commonly present in human existence and culture, such as social networks, distribution of wealth (Pareto's principle), or the results of surveys and polls.
...